vim下:nginx配置文件 nginx.conf多行注释
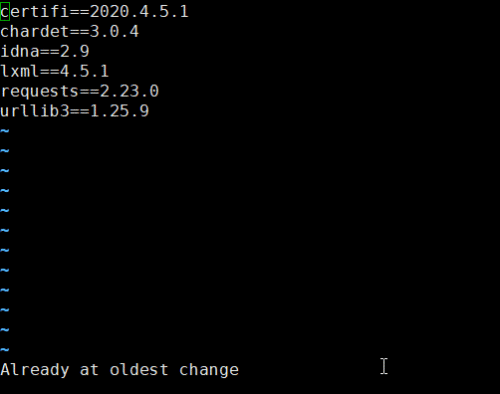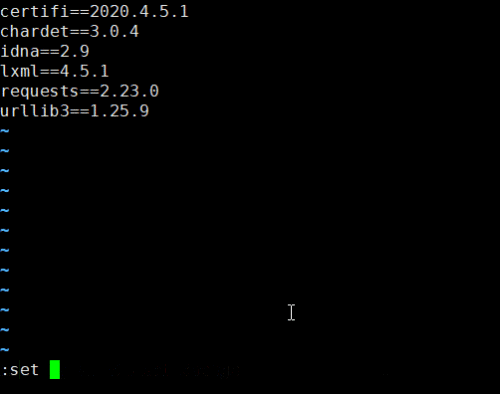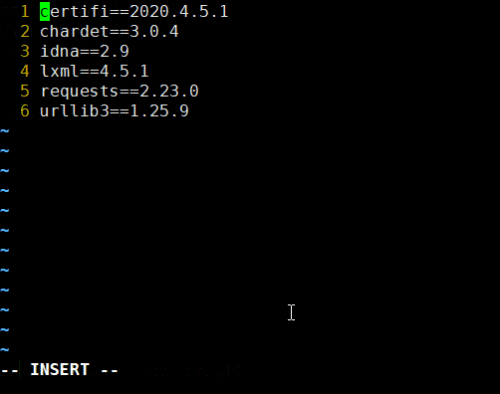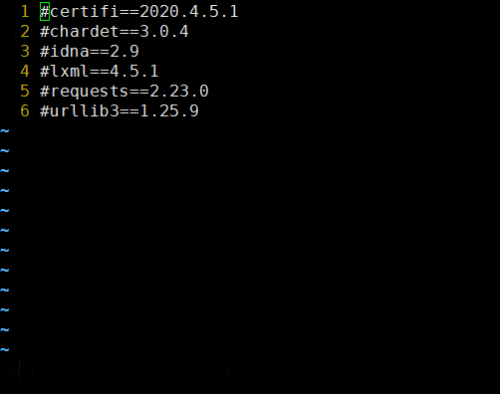
vim下:nginx配置文件 nginx.conf多行注释
Vue3环境下ECharts图表的Tooltip不显示的问题的解决方法
 无枫丶2022-12-26 02:21:35
无枫丶2022-12-26 02:21:35
最近在Vue3项目中使用ECharts5.0制作统计图表,发现配置一切正常,但是tooltip无论如何就是无法显示,所以排查了下原因,发现是ECharts与Vue的响应性特性存在兼容性问题。
ECharts在Vue3环境下,使用ECharts5.0+版本会出现该问题。原因是echarts实例不能由Vue来维护(Vue的响应性特性)。
所以将原来的代码:
其中,xxxGraph字段为ECharts的示例,目前他位于 data() 的 return 中,由Vue来进行响应性维护。
- export default {
- data () {
- return {
- xxxGraph: null
- }
- },
- mounted () {
- this.xxxGraph = echarts.init(document.getElementById('xxxGraph'))
- }
- }
更改为如下代码:
其中,xxxGraph字段为ECharts的示例,目前它位于 data() 中,但位于return外,这时xxxGraph不会具备Vue的响应性特性。
- export default {
- data () {
- this.xxxGraph = null
- return {
- // ...
- }
- },
- mounted () {
- this.xxxGraph= echarts.init(document.getElementById('xxxGraph'))
- }
- }
按照如上方法更改后,可以刷新页面尝试一下看看是否可以正常显示tooltip了。
在Vue3.0版本中,只要你确保你的echarts实例不是响应式的,那么tooltip就可以正常显示,目前暂时没有发现在Vue3.0环境中,由于响应性实例对象带来的其他问题。理论上通过该方法均可以进行解决。
之前在Vue2.0版本中,使用相同版本的ECharts,并没有出现该问题,可能是我的ECharts版本没有适配Vue3.0的原因吧,暂时没有尝试更新ECharts版本,先按照本文的代码修改了。后续有时间的话会尝试下新版本的ECharts在Vue3.0版本中是否可以按照正常写法成功显示tooltip。
JavaScript中 with的用法
 zwkkkk12018-03-28 12:50:09
zwkkkk12018-03-28 12:50:09
说起js中的with关键字,很多小伙伴们的第一印象可能就是with关键字的作用在于改变作用域,然后最关键的一点是不推荐使用with关键字。听到不推荐with关键字后,我们很多人都会忽略掉with关键字,认为不要去管它用它就可以了。但是有时候,我们在看一些代码或者面试题的时候,其中会有with关键字的相关问题,很多坑是你没接触过的,所以还是有必要说说with这一个关键字。
with 语句的原本用意是为逐级的对象访问提供命名空间式的速写方式. 也就是在指定的代码区域, 直接通过节点名称调用对象。
with 通常被当做重复引用同一个对象中的多个属性的快捷方式,可以不需要重复引用对象本身。
比如,目前现在有一个这样的对象:
var obj = {
a: 1,
b: 2,
c: 3
};
如果想要改变 obj 中每一项的值,一般写法可能会是这样:
// 重复写了3次的“obj”
obj.a = 2;
obj.b = 3;
obj.c = 4;
而用了 with 的写法,会有一个简单的快捷方式
with (obj) {
a = 3;
b = 4;
c = 5;
}
在这段代码中,使用了 with 语句关联了 obj 对象,这就以为着在 with 代码块内部,每个变量首先被认为是一个局部变量,如果局部变量与 obj 对象的某个属性同名,则这个局部变量会指向 obj 对象属性。
在上面的例子中,我们可以看到,with 可以很好地帮助我们简化代码。但是为什么不推荐使用呢?下面我们来说说with的缺点:
我们来看下面的这部分代码
function foo(obj) {
with (obj) {
a = 2;
}
}
var o1 = {
a: 3
};
var o2 = {
b: 3
}
foo(o1);
console.log(o1.a); //2
foo(o2);
console.log(o2.a); //underfined
console.log(a); //2,a被泄漏到全局作用域上
首先,我们来分析上面的代码。例子中创建了 o1 和 o2 两个对象。其中一个有 a 属性,另外一个没有。foo(obj) 函数接受一个 obj 的形参,该参数是一个对象引用,并对该对象引用执行了 with(obj) {...}。在 with 块内部,对 a 有一个词法引用,实际上是一个 LHS引用,将 2 赋值给了它。
当我们将 o1 传递进去,a = 2 赋值操作找到了 o1.a 并将 2 赋值给它。而当 o2 传递进去,o2 并没有 a 的属性,因此不会创建这个属性,o2.a 保持 undefined。
但为什么对 o2的操作会导致数据的泄漏呢?
这里需要回到对 LHS查询 的机制问题(详情可移步 JavaScript中的LHS和RHS查询)。
当我们传递 o2 给 with 时,with 所声明的作用域是 o2, 从这个作用域开始对 a 进行 LHS查询。o2 的作用域、foo(…) 的作用域和全局作用域中都没有找到标识符 a,因此在非严格模式下,会自动在全局作用域创建一个全局变量),在严格模式下,会抛出ReferenceError 异常。
另一个不推荐 with 的原因是。在严格模式下,with 被完全禁止,间接或非安全地使用 eval(…) 也被禁止了。
with 会在运行时修改或创建新的作用域,以此来欺骗其他在书写时定义的词法作用域。with 可以使代码更具有扩展性,虽然有着上面的数据泄漏的可能,但只要稍加注意就可以避免,难道不是可以创造出很好地功能吗?
答案是否定的,具体原因我们先来看下面的这部分代码。
下面代码可以直接复制出去运行
<script>
function func() {
console.time("func");
var obj = {
a: [1, 2, 3]
};
for(var i = 0; i < 100000; i++)
{
var v = obj.a[0];
}
console.timeEnd("func");
}
func();
function funcWith() {
console.time("funcWith");
var obj = {
a: [1, 2, 3]
};
with(obj) {
for(var i = 0; i < 100000; i++) {
var v = a[0];
}
}
console.timeEnd("funcWith");
}
funcWith();
</script>
接着是,测试效果:

在处理相同逻辑的代码中,没用 with 的运行时间仅为 4.63 ms。而用 with 的运用时间长达 81.87ms。
这是为什么呢?
原因是 JavaScript 引擎会在编译阶段进行数项的性能优化。其中有些优化依赖于能够根据代码的词法进行静态分析,并预先确定所有变量和函数的定义位置,才能在执行过程中快速找到标识符。
但如果引擎在代码中发现了 with,它只能简单地假设关于标识符位置的判断都是无效的,因为无法知道传递给 with 用来创建新词法作用域的对象的内容到底是什么。
最悲观的情况是如果出现了 with ,所有的优化都可能是无意义的。因此引擎会采取最简单的做法就是完全不做任何优化。如果代码大量使用 with 或者 eval(),那么运行起来一定会变得非常慢。无论引擎多聪明,试图将这些悲观情况的副作用限制在最小范围内,也无法避免如果没有这些优化,代码会运行得更慢的事实。
Git分支改名命令
 云原生手记2018-08-23 10:25:54
云原生手记2018-08-23 10:25:54
1. 如果对于分支不是当前分支,可以使用下面的命令:
git branch -m "原分支名" "新分支名"
2. 如果是当前分支:
git branch -m "新分支名称"
Stream 流中 Collectors.toMap 的用法
 致最长的电影2023-06-21 16:59:00
致最长的电影2023-06-21 16:59:00
Collectors.toMap() 方法是把 List 转 Map 的操作
- public static void main(String[] args) {
- List<Student> list = Arrays.asList(
- new Student(1, "张三", 20, "29.8"),
- new Student(2, "李四", 25, "29.5"),
- new Student(3, "赵武", 23, "30.8"),
- new Student(4, "王六", 22, "31.8")
- );
-
- list 打印输出为:[
- Student(id=1, name=张三, age=20, score=29.8),
- Student(id=2, name=李四, age=25, score=29.5),
- Student(id=3, name=赵武, age=23, score=30.8),
- Student(id=4, name=王六, age=22, score=31.8)
- ]
-
-
/**
* id 作为 map 的key,name 作为 value
* 结果集: {1=张三, 2=李四, 3=赵武, 4=王六}
*/- Map<Integer, String> collect = list.stream()
- .collect(Collectors.toMap(Student::getId, Student::getName));
- System.out.println(collect);
-
-
/**
* id 作为 map 的 key,Student 对象作为 map 的 value
* 结果集: {1=Student(id=1, name=张三, age=20, score=29.8),
2=Student(id=2, name=李四, age=25, score=29.5),
3=Student(id=3, name=赵武, age=23, score=30.8),
4=Student(id=4, name=王六, age=22, score=31.8)}
*/- Map<Integer, Student> collect1 = list.stream()
- .collect(Collectors.toMap(Student::getId, v -> v));
- System.out.println(collect1);
-
-
/**
* id 作为 map 的 key,Student 对象作为 map 的 value
* 结果集: {1=Student(id=1, name=张三, age=20, score=29.8),
2=Student(id=2, name=李四, age=25, score=29.5),
3=Student(id=3, name=赵武, age=23, score=30.8),
4=Student(id=4, name=王六, age=22, score=31.8)}
*/- Map<Integer, Student> collect2 = list.stream()
- .collect(Collectors.toMap(Student::getId, Function.identity()));
- System.out.println(collect2);
- }
- String typeBanner = "A=1,B=2,C=3";
- String[] typeBannerArray = typeBanner.split(",");
- System.out.println(Arrays.toString(typeBannerArray)); // [A=1, B=2, C=3]
- Map<String, String> typeBannerMap = Arrays.stream(typeBannerArray).collect(Collectors.toMap(
- (array) -> array.split("=")[0],
- (array) -> array.split("=")[1]
- ));
- System.out.println(typeBannerMap); // {A=1, B=2, C=3}
按照规范来写的话,最好所有toMap,都要将这个异常提前考虑进去,不然有时候会报重复主键异常,这也是正例的写法,上面的属于反例的写法。
- toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper);
- toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
- BinaryOperator<U> mergeFunction);
- toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
- BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier);
参数解释:
1. keyMapper:Key 的映射函数,Student:getId 表示选择 Student 的 getId 作为 map 的 key 值。
2. valueMapper:Value的映射函数,Function.identity() 表示选择将原来的对象作为 Map 的value 值。
3. mergeFunction:当 Key 冲突时,调用的合并方法。(n1,n2)->n1 中,如果 n1 与 n2 的 key 值相同,选择 n1 作为那个 key 所对应的 value 值。
4. mapSupplier:Map 构造器,在需要返回特定的 Map 时使用。第四个参数 mapSupplier 用于返回一个任意类型的 Map 实例,比如我们希望返回的 Map 是根据 Key 排序的。TreeMap::new
- public static void main(String[] args) {
- List<Student> list = Arrays.asList(
- new Student(1, "张三", 20, "29.8"),
- new Student(2, "李四", 25, "29.5"),
- new Student(1, "赵武", 23, "30.8"),
- new Student(4, "王六", 22, "31.8")
- );
- /**
- * id 作为 map 的key,重复 id 的 name 合并作为 value
- * 结果集: {1=张三,赵武, 2=李四, 4=王六}
- */
- Map<Integer, String> collect = list.stream()
- .collect(Collectors.toMap(Student::getId, Student::getName, (n1, n2) -> n1 +","+ n2));
- System.out.println(collect);
-
- /**
- * 取前面一个 Student 对象
- * 结果集: {1=Student(id=1, name=张三, age=20, score=29.8),
- 2=Student(id=2, name=李四, age=25, score=29.5),
- 4=Student(id=4, name=王六, age=22, score=31.8)}
- */
- Map<Integer, Student> collect1 = list.stream()
- .collect(Collectors.toMap(Student::getId, Function.identity(), (n1, n2) -> n1));
- System.out.println(collect1);
-
- /**
- * 取后面一个 Student 对象
- * 结果集: {1=Student(id=1, name=赵武, age=23, score=30.8),
- 2=Student(id=2, name=李四, age=25, score=29.5),
- 4=Student(id=4, name=王六, age=22, score=31.8)}
- */
- Map<Integer, Student> collect2 = list.stream()
- .collect(Collectors.toMap(Student::getId, Function.identity(), (n1, n2) -> n2, TreeMap::new));
- System.out.println(collect2);
- }
写案例遇到的问题有,上述第一个输出,如果写成 n1 + n2 ,map 第二个参数类型是对象或者是list集合,都是显示编译报错状态。
Java try catch 跳过了catch直接进入finally
css样式中的百分比都是相对于谁的?
 huangpb06242022-03-15 22:00:03
huangpb06242022-03-15 22:00:03
width、height(正常定位)
width 和 height 的百分比是分别根据父级元素块的宽度和高度来计算的。
相对定位的 top、left
- position: relative;
- top: 100%;
- left: 100%;
top 和 left 的百分比是分别根据父级元素块的高度和宽度来计算的。
绝对定位的 top、left、width、height
- position: absolute;
- top: 50%;
- left: 50%;
-
- width: 100%;
- height: 100%;
top、height 和 left、width 的百分比是分别根据包含它的第一个不是 static 定位的元素的高度和宽度来计算的。
固定定位的 top、left
- position: fixed;
- top: 50%;
- left: 50%;
top 和 left 的百分比是分别根据浏览器视口的高度和宽度来计算的。
translate
transform: translate(-50%, -50%);translate 是根据自身的宽高来计算的。
margin-top, margin-left,padding-top, padding-left
- margin-top: 50%;
- margin-left: 50%;
相对于父级元素块的宽度。
border-radius
border-radius: 50%;相对于自身。
background-size
background-size: 100% 100%;相对背景区的宽高。
CSS解决position:fixed基于父元素定位而不是浏览器窗口
 1024_Byte2022-03-08 15:08:31
1024_Byte2022-03-08 15:08:31
众所周知fixed是基于浏览器窗口定位,但是今天遇到个问题,发现fixed并不一定是这样
有一个例外会使fixed是基于祖先元素定位。


<div class="container" style="transform:rotate(360deg);">
<div>
<div class="box" style="position:fixed;"></div>
</div>
</div>
el-table组件自带了一个transform属性

fixed不为元素预留空间,而是通过指定元素相对于屏幕视口(viewport)的位置来指定元素位置。元素的位置在屏幕滚动时不会改变。打印时,元素会出现在的每页的固定位置。fixed 属性会创建新的层叠上下文。当元素祖先的 transform 属性非 none 时,容器由视口改为该祖先。
(会产生副作用, 会影响其他的定位)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>1</title>
<style>
.test {
position: fixed;
left: 0;
right: 0;
bottom: 0;
width: 600px;
margin: 0 auto;
background-color: green;
}
</style>
</head>
<body>
<div class="test">22</div>
</body>
</html>
notepad++录制宏:删除整行
 美酒 + 咖啡2023-12-28 14:59:29
美酒 + 咖啡2023-12-28 14:59:29
springcloud @EnableDiscoveryClient注解作用
 笑是神的伪装2018-09-06 18:46:51
笑是神的伪装2018-09-06 18:46:51
相信熟悉Spring Cloud的读者对注解@EnableDiscoveryClient 及@EnableEurekaClient 并不陌生。
要想将一个微服务注册到Eureka Server(或其他服务发现组件,例如Zookeeper、Consul等),Eureka 2.0闭源之后,Consul慢慢会成为主流。
只需:
添加Eureka Client(或其他服务发现组件的Client)依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
写注解:在启动类上添加注解@EnableDiscoveryClient 或@EnableEurekaClient
@EnableDiscoveryClient
@SpringBootApplication
public class ProviderUserApplication {
public static void main(String[] args) {
SpringApplication.run(ProviderUserApplication.class, args);
}
}
|
写配置:
spring:
application:
name: microservice-provider-user
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
|
从Spring Cloud Edgware开始,@EnableDiscoveryClient 或@EnableEurekaClient 可省略。只需加上相关依赖,并进行相应配置,即可将微服务注册到服务发现组件上。
@EnableDiscoveryClient和@EnableEurekaClient共同点就是:都是能够让注册中心能够发现,扫描到改服务。
不同点:@EnableEurekaClient只适用于Eureka作为注册中心,@EnableDiscoveryClient 可以是其他注册中心。
花5分钟过一遍jar包和war包的区别(概念,目录,使用和部署)
解决IDEA不能直接运行单个JAVA文件
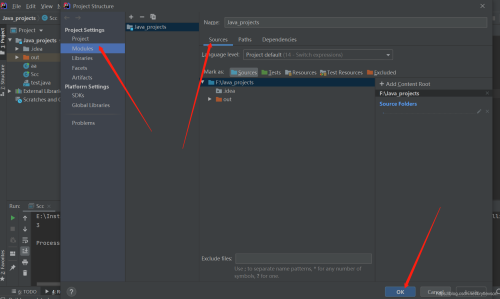
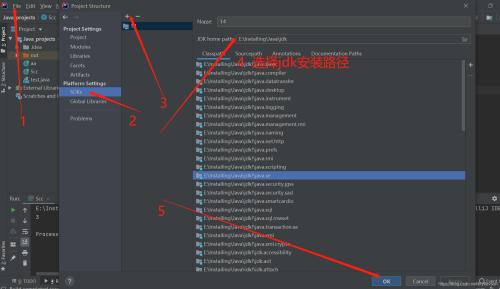
IntelliJ IDEA配置JDK版本
css选择器 ~ (波浪号)、+(加号)、>(大于号)的用法解析和举例

IntelliJ IDEA 设置终端(Terminal) 打开时默认位置
 负熵流2024-06-26 11:44:27
负熵流2024-06-26 11:44:27
打开设置: 在 IntelliJ IDEA 中,通过点击菜单栏的 File -> Settings (Windows/Linux) 或 IntelliJ IDEA -> Preferences (macOS)。
定位到 Terminal 设置: 在设置窗口中,找到 Tools -> Terminal。
修改启动目录: 在 Terminal 设置中,你可以找到一个选项 Start directory。如果你希望 Terminal 始终在当前项目的根目录打开,可以使用特定的宏来设置路径。例如:
$ProjectFileDir$,这样 Terminal 将会在你打开的项目根目录下启动。保存并关闭设置: 点击 OK 或 Apply 来保存你的设置。